__NUXT_DATA__ : reverse engineering du format de sérialisation de Nuxt 3
Ce que j’ai trouvé en ouvrant le code source d’une page Nuxt
Je buildais un serveur MCP pour interagir avec une marketplace freelance. Le but : permettre à un LLM d’aller chercher des profils, des compétences, des disponibilités — sans passer par une API publique parce qu’il n’y en a pas.
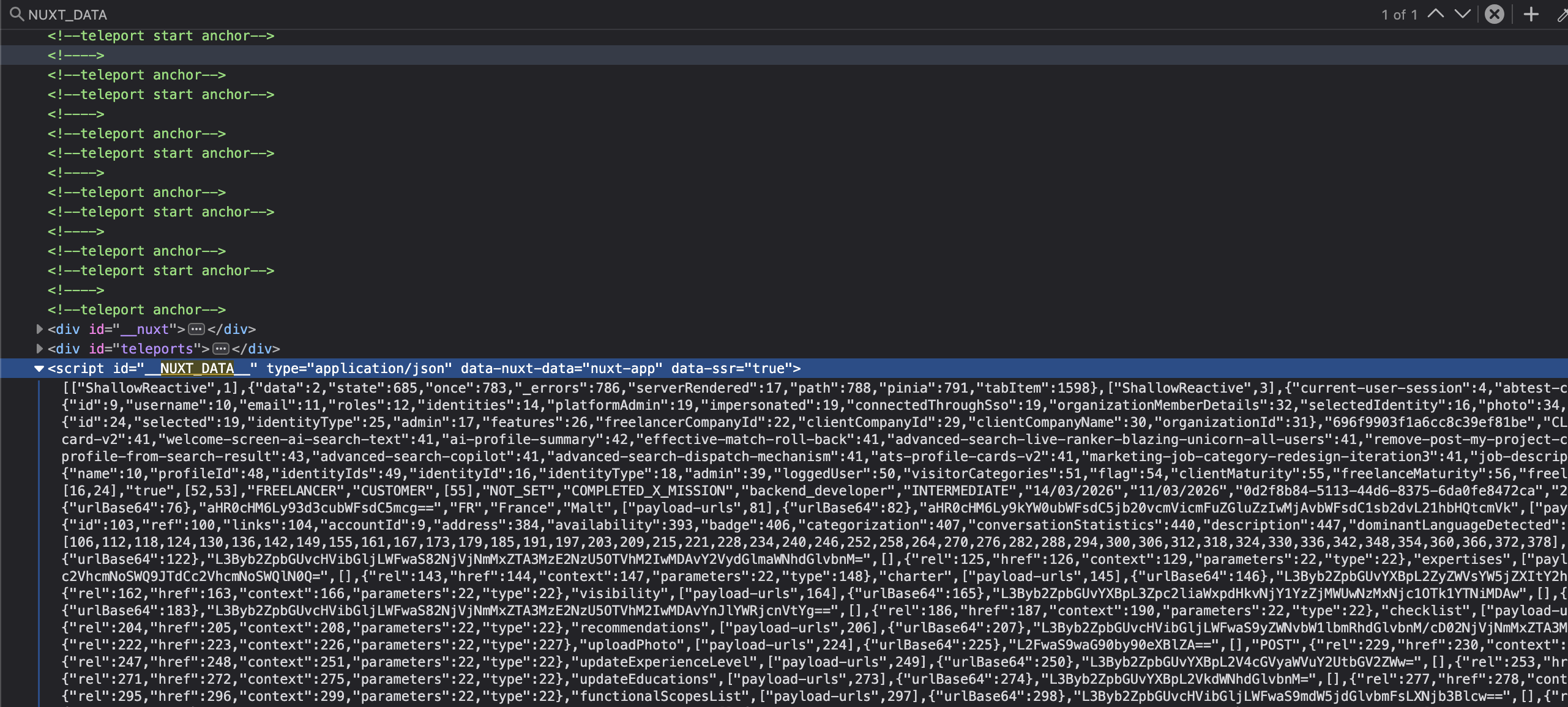
Première approche : regarder le HTML de la page profil et extraire ce dont j’ai besoin. J’ouvre le source dans le navigateur, je cherche le nom, le job title, les skills… et je tombe sur ça :
<script id="__NUXT_DATA__" type="application/json">
[0,1,2,3,4,"Alice","full-stack",42,{"name":5,"job":6,"age":7},...]
</script>Plusieurs milliers d’entrées. Des nombres partout, quelques strings perdues au milieu, des objets avec des valeurs numériques qui n’ont aucun sens. Mon premier réflexe : chercher la doc. Nuxt documente ça quelque part forcément. Spoiler : non.
J’ai passé un bon moment à fixer ce tableau en me demandant pourquoi name vaut 5 dans un objet qui représente un profil humain. Sauf que, 5, c’est pas une valeur. C’est un indice, une sorte de pointeur. La vraie valeur est ailleurs dans le tableau, à l’index 5.
Voilà ce que c’est vraiment, et pourquoi c’est pas trivial à parser.
Un tableau plat où tout se référence par indice
devalue — la librairie que Nuxt utilise pour sérialiser l’état SSR — ne stocke pas les objets comme du JSON classique. Au lieu de ça, il aplatit tout en un seul tableau et remplace chaque valeur par un indice vers une autre entrée du tableau.
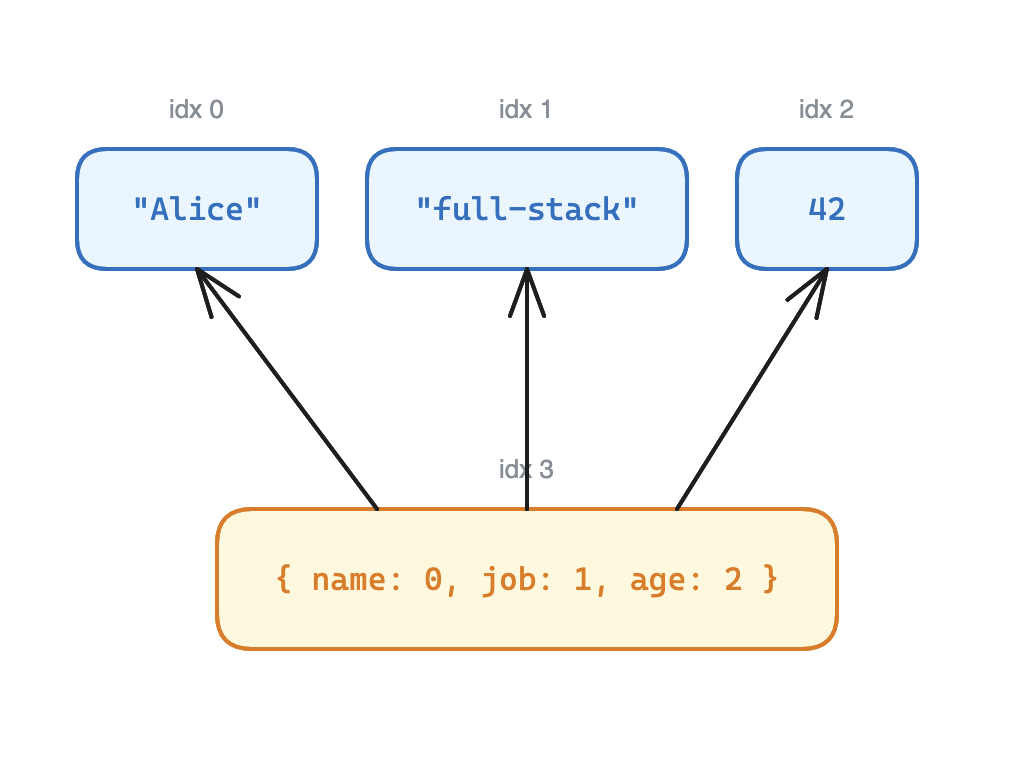
Concrètement, l’objet { name: "Alice", job: "full-stack", age: 42 } devient :
["Alice", "full-stack", 42, { "name": 0, "job": 1, "age": 2 }]L’objet est à l’index 3. name: 0 ne signifie pas que name vaut 0, ça signifie “la valeur de name est à l’index 0”, soit "Alice". Même chose pour job (index 1 → "full-stack") et age (index 2 → 42).
La raison est assez simple: si le même objet est référencé à 15 endroits dans l’app, il n’est stocké qu’une seule fois, ce qui fait que les 15 références pointent vers le même indice. Zéro duplication, une optimisation parfaite des informations, mais impossible à lire directement.
En résumé, pour extraire quoi que ce soit, il faut d’abord écrire un résolveur récursif qui suit ces pointeurs.
function resolve(idx: number): unknown {
const val = raw[idx];
if (typeof val !== 'object' || val === null) return val;
if (Array.isArray(val)) {
return val.map((item) => (typeof item === 'number' ? resolve(item) : item));
}
return Object.fromEntries(
Object.entries(val).map(([k, v]) => [k, typeof v === 'number' ? resolve(v) : v])
);
}resolve(3) sur le tableau ci-dessus parcourt l’objet, remplace 0 par resolve(0) → "Alice", 1 par resolve(1) → "full-stack", 2 par resolve(2) → 42. Résultat final : { name: "Alice", job: "full-stack", age: 42 }.
Le problème des références circulaires
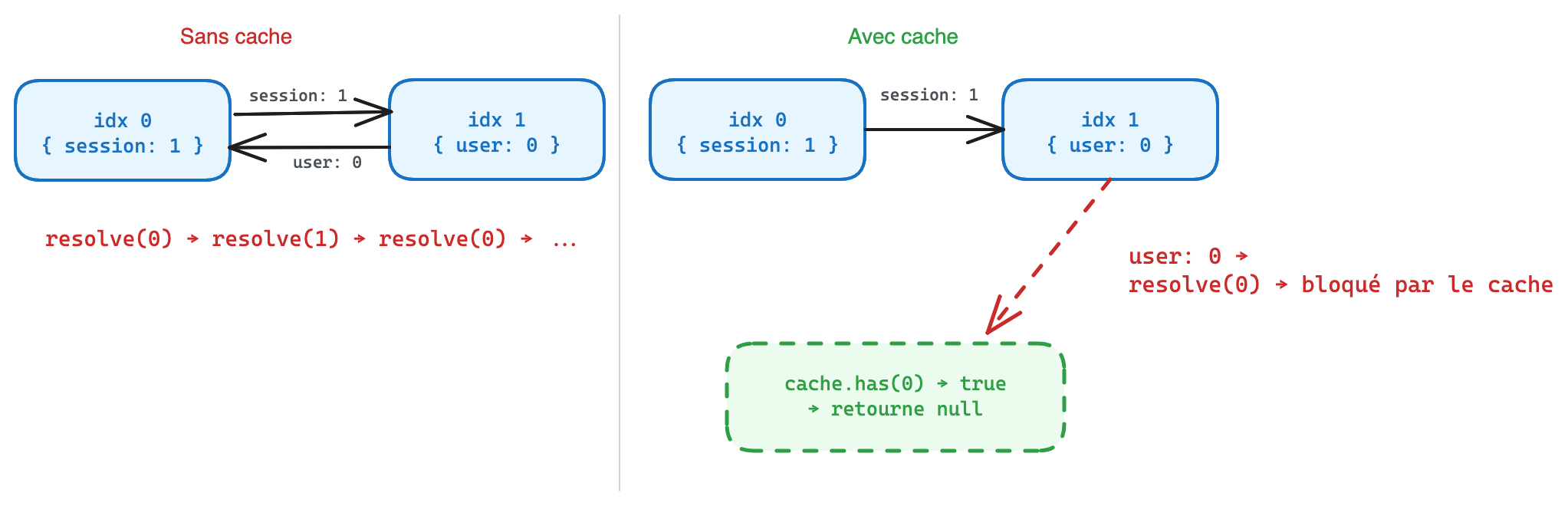
Sur une app réelle avec des stores Pinia, le format génère des refs circulaires. Ça ressemble à ça dans le payload brut :
[
{ "user": 1, "session": 2 },
{ "profile": 0, "name": 3 },
{ "token": 4, "user": 1 },
"Alice",
"abc123"
]index 0 référence index 1, qui référence index 0. Sans protection, le résolveur boucle à l’infini.
Pour régler ce problème, il nous faut un cache avec un sentinel null posé avant de commencer la résolution d’un index. Si on retombe sur ce même index pendant qu’on le résout déjà, on retourne null au lieu de boucler. Une fois la résolution terminée, on remplace le sentinel par le vrai résultat.
const cache = new Map<number, unknown>();
function resolve(idx: number): unknown {
if (cache.has(idx)) return cache.get(idx);
cache.set(idx, null); // sentinel — coupe la boucle si on revient ici
const val = raw[idx];
// ... résolution ...
cache.set(idx, result);
return result;
}Sur le payload de la plateforme freelance dont je tairais le nom, des dizaines de stores se référencent mutuellement. Sans ce mécanisme, le parser explose sur les premières entrées.
Les types tagués — et ce que chaque app y ajoute
devalue encode certains types JavaScript avec des tableaux tagués : le premier élément identifie le type, le reste ce sont les arguments.
["Date", "2024-01-15"]
["Set", 1, 2, 3]
["RegExp", "foo", "gi"]
["BigInt", "123"]Ces tableaux sont dans le même tableau plat que le reste — mélangés avec les objets et les primitives. Pour les distinguer d’un vrai tableau de données, devalue utilise une convention : si le premier élément est un string, c’est une instruction de désérialisation, pas une valeur. Le string dit quoi faire, le reste dit avec quoi. Le résolveur vérifie ça en premier et sait quoi construire.
Pour les valeurs scalaires qu’on ne peut pas représenter en JSON classique, devalue utilise des indices négatifs dans les objets :
{ "v": -1 } → { v: undefined }
{ "v": -3 } → { v: NaN }
{ "v": -4 } → { v: Infinity }
{ "v": -5 } → { v: -Infinity }
{ "v": -6 } → { v: -0 }-2 est un trou dans un sparse array ([1, , 3]), -7 marque le tableau lui-même comme sparse. C’est documenté nulle part dans Nuxt, il faut lire le code source de devalue pour le trouver.
Nuxt ajoute ses propres types par-dessus, pour les wrappers de réactivité Vue :
["Ref", 7]
["ShallowReactive", 12]
["EmptyRef"]["Ref", 7] signifie : un ref() Vue dont la valeur est à l’index 7. Pour l’extraction de données, on s’en fout de la réactivité — on résout juste 7 directement.
Et là où ça devient vraiment intéressant : chaque application Nuxt peut définir ses propres types. Sur la marketplace que j’analysais, il y avait :
["Profile", 3]
["Experiences", 8]
["Appraisals", 15]
["SkillSet", 22]Des dizaines de types inventés par l’app, sérialisés avec le même mécanisme. Le deuxième élément est toujours un indice vers la valeur réelle. Un default dans le résolveur suffit à tous les gérer sans les connaître à l’avance :
default:
// App-defined type — résout le premier argument
return resolve(tag[1] as number)C’est ce qui rend le parser générique : il fonctionne sur n’importe quelle app Nuxt, même sans connaître ses types métier.
Explorer le payload sans savoir ce qu’il contient
Le premier problème concret : sur une page inconnue, on ne sait pas quels types existent, ni où sont les données utiles. Le tableau peut avoir 3 000 entrées.
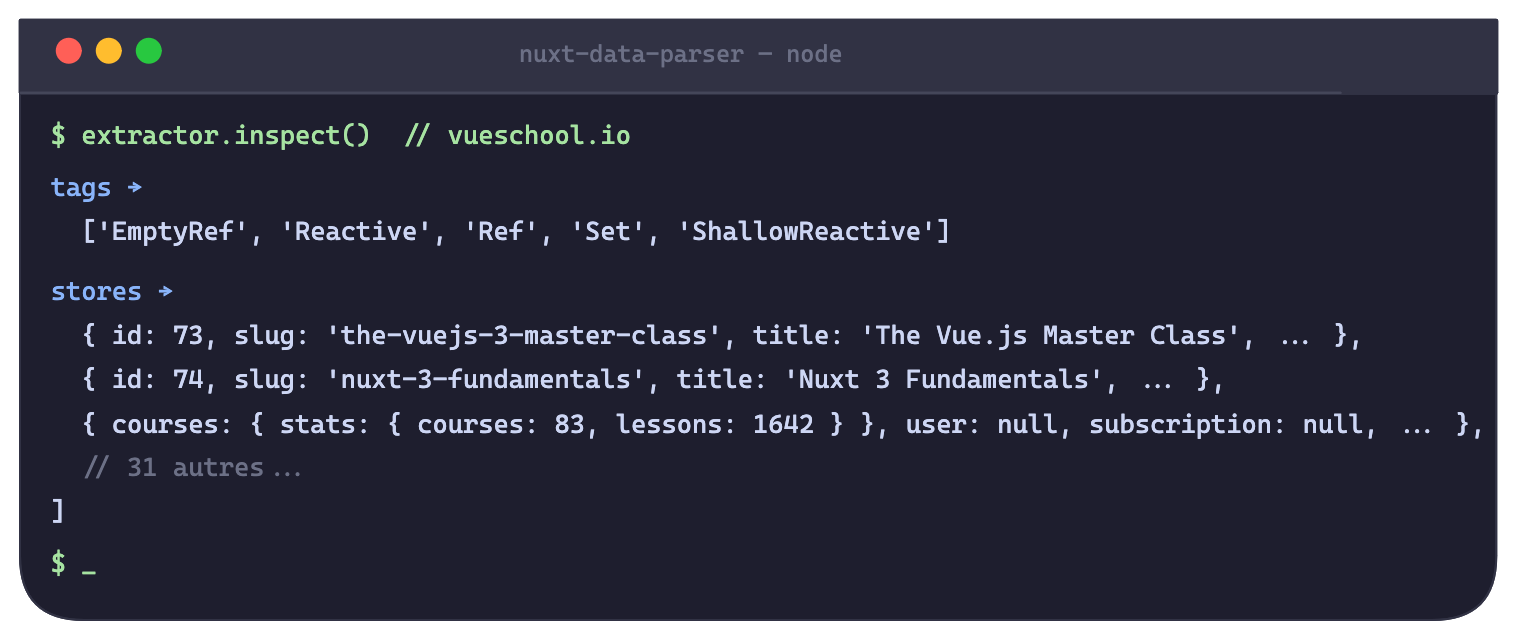
J’ai ajouté une méthode inspect() qui scanne le payload et remonte deux choses :
const { tags, stores } = extractor.inspect();tags liste tous les noms de types présents dans le payload :
['Appraisals', 'Date', 'EmptyRef', 'Experiences', 'Profile', 'Ref', 'SkillSet', ...]C’est le premier truc à appeler sur une app inconnue, ça donne immédiatement la liste des types métier qu’on peut extraire avec findByType.
stores retourne les objets résolus avec plus de 8 clés. Les stores Pinia sont les objets plats les plus denses du payload — c’est l’heuristique qui marche dans la pratique.
Retrouver les stores Pinia là-dedans
Les stores Pinia sont sérialisés dans le tableau comme n’importe quel autre objet, sans marqueur explicite. Pas de clé "_pinia", pas de header, ils sont juste là, indiscernables des autres objets, jusqu’à ce qu’on les résolve.
Ce que retourne stores sur la marketplace :
[
{ accessToken: null, userId: null, isLoggedIn: false, ... }, // session store
{ displayName: 'Alice', jobTitle: 'Dev full-stack', skills: [...] }, // profile store
{ results: [...], total: 48, filters: { ... } }, // search store
// ...
]Pour cibler un store précis dont on connaît les clés, duck-typing :
const store = extractor.getPiniaStore(['displayName', 'jobTitle', 'skills']);Résultat : tout l’état du store profile — sans toucher à une API, sans avoir de session authentifiée, directement depuis le HTML de la page publique.
Ce que j’en ai fait
J’ai packagé tout ça dans nuxt-data-parser, zero-dependency, browser + Node.
import { extractFromUrl } from 'nuxt-data-parser';
const ex = await extractFromUrl('https://example.com/page');
// Explorer ce qui est disponible
const { tags } = ex.inspect();
// → ['Date', 'Experience', 'Profile', 'Ref', ...]
// Extraire un type spécifique, avec le typage TypeScript
const profile = ex.findByType<MonProfil>('Profile');
const exps = ex.findAllByType<Experience>('Experience');
// Ou résoudre n'importe quel index directement
const val = ex.resolve(42);Le package couvre la totalité du format devalue — types built-in, sentinels négatifs, TypedArrays, références circulaires, types app-définis. findByType<T> est générique, donc le résultat est typé si vous passez votre interface.
Si vous avez déjà ouvert le source d’une page Nuxt et vu ce tableau illisible, maintenant vous savez ce que c’est, et y’a un outil pour le lire.